登录和授权
登录和授权的区别
- 登录:身份认证,即确认「你是你」的过程。
- 授权:由身份或持有的令牌确认享有某些权限(例如获取⽤户信息)。⽽登录过程实质上的⽬的也是为了确认权限。
因此,在实际的应⽤中,多数场景下的「登录」和「授权」界限是模糊的。
-
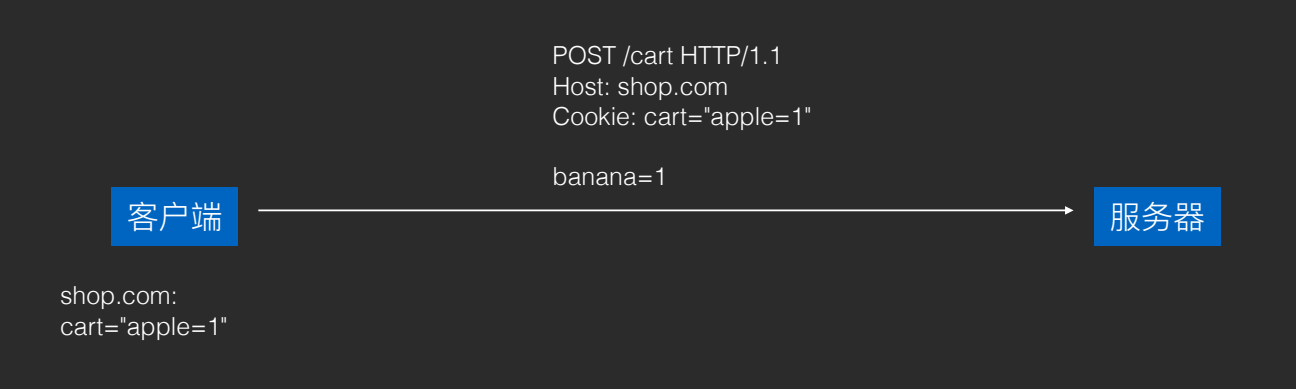
起源:「购物⻋」功能的需求,由 Netscape 浏览器开发团队打造。
-
⼯作机制:
- 服务器需要客户端保存的内容,放在 Set-Cookie headers ⾥返回,客户端会⾃动保存。

-
Cookie 的作⽤
- 会话管理:登录状态、购物⻋ ( sessionid )
- 个性化:⽤户偏好、主题
- Tracking:分析⽤户⾏为
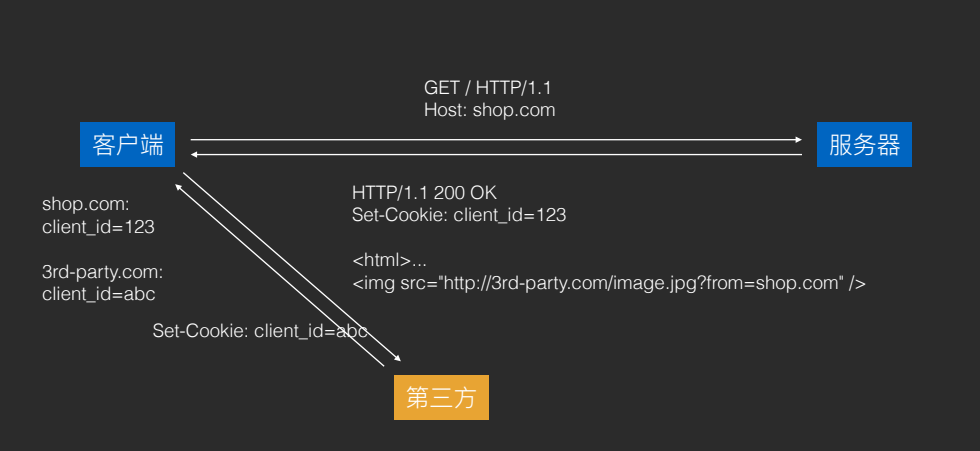
- XSS (Cross-site scripting) :跨站脚本攻击。即使⽤ JavaScript 拿到浏览器的 Cookie 之后,发送到⾃⼰的⽹站,以这种⽅式来盗取⽤户Cookie。应对⽅式:Server 在发送 Cookie 时,敏感的 Cookie 加上HttpOnly。
- 应对⽅式:HttpOnly——这个 Cookie 只能⽤于 HTTP 请求,不能被 JavaScript 调⽤。它可以防⽌本地代码滥⽤ Cookie。
- XSRF (Cross-site request forgery)(了解即可):跨站请求伪造。即在⽤户不知情的情况下访问已经保存了 Cookie 的⽹站,以此来越权操作⽤户账户(例如盗取⽤户资⾦)。
- 应对⽅式:Referer 校验。


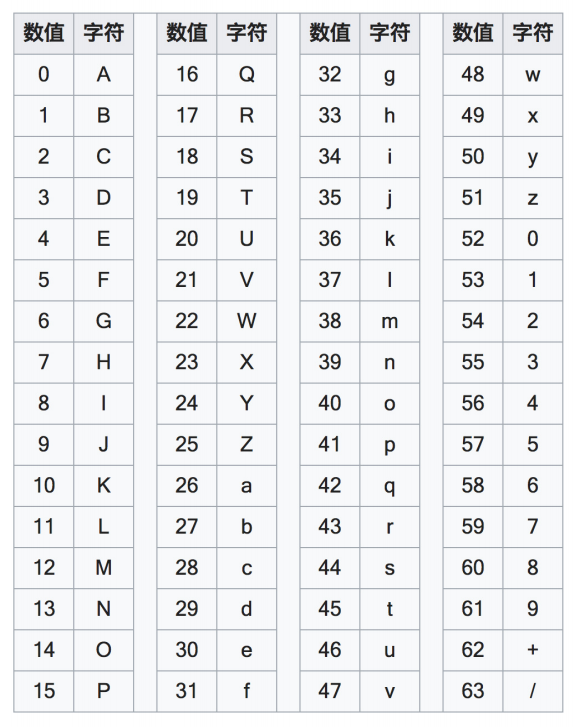
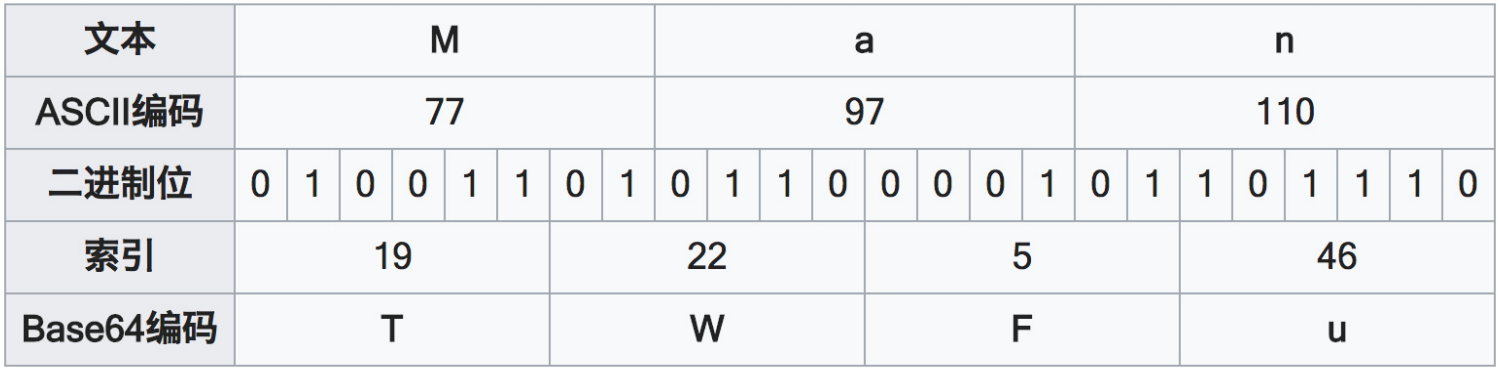
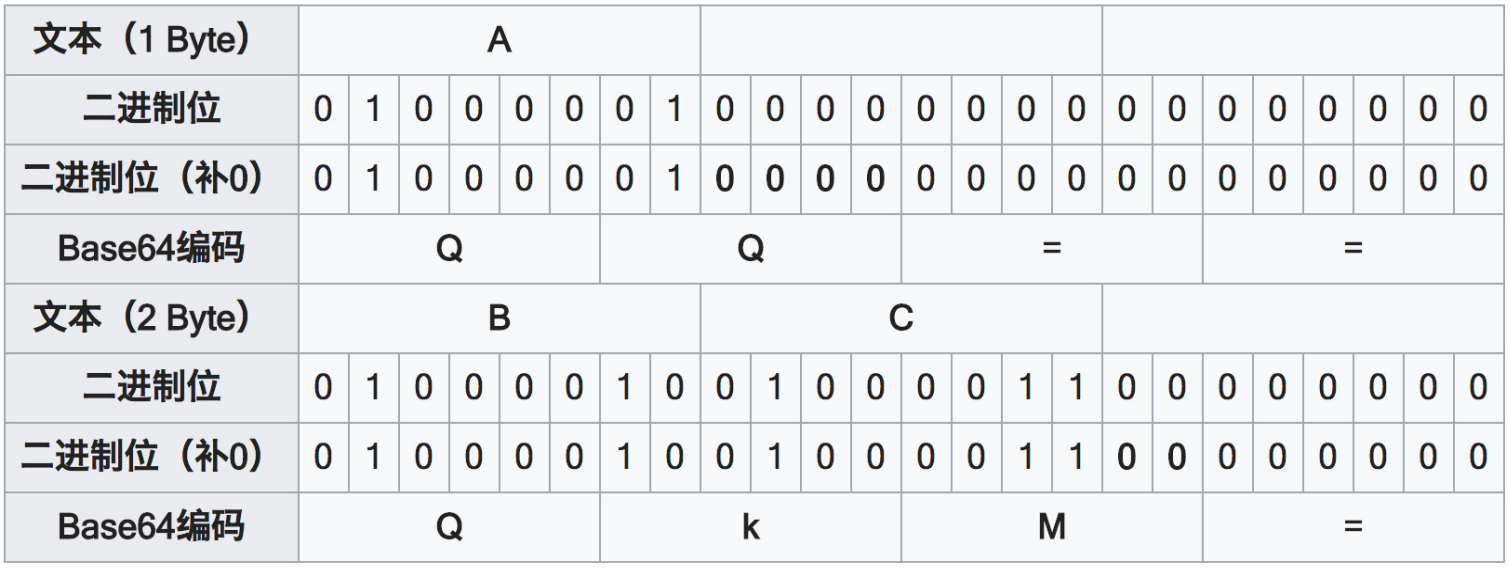
Basic
- 格式:Authorization : Basic username:password(Base64ed)
Bearer
-
格式:Authorization: Bearer
-
bearer token 的获取⽅式:通过 OAuth2 的授权流程。
-
OAuth2 的流程 :
-
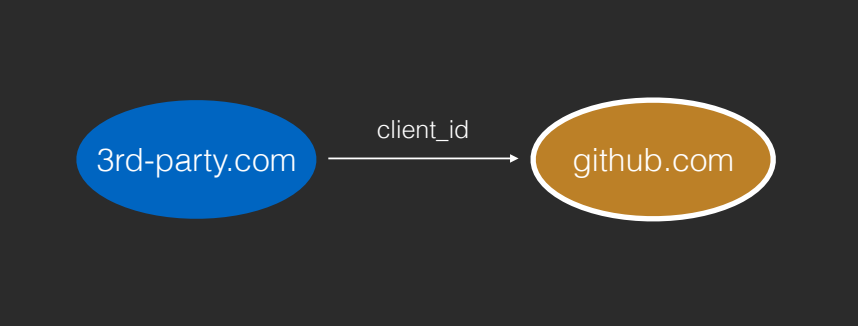
第三⽅⽹站向授权⽅⽹站申请第三⽅授权合作,拿到 client id 和 client secret
-
⽤户在使⽤第三⽅⽹站时,点击「通过 XX (如 GitHub) 授权」按钮,第三⽅⽹站将⻚⾯跳转到授权⽅⽹站,并传⼊ client id 作为⾃⼰的身份标识
-
授权⽅⽹站根据 client id ,将第三⽅⽹站的信息和第三⽅⽹站需要的⽤户权限展示给⽤户,并询问⽤户是否同意授权
-
⽤户点击「同意授权」按钮后,授权⽅⽹站将⻚⾯跳转回第三⽅⽹站,并传⼊ Authorization code 作为⽤户认可的凭证。

-
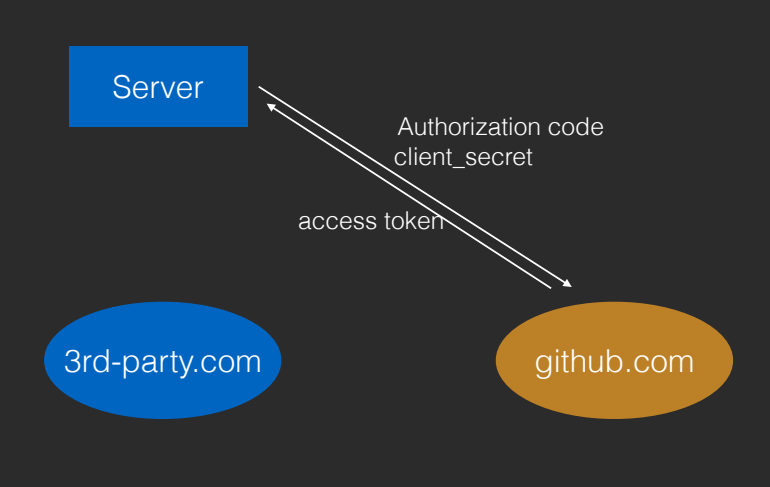
第三⽅⽹站将 Authorization code 发送回⾃⼰的服务器

-
服务器将 Authorization code 和⾃⼰的 client secret ⼀并发送给授权⽅的服务器,授权⽅服务器在验证通过后,返回 access token。OAuth 流程结束。
-
在上⾯的过程结束之后,第三⽅⽹站的服务器(或者有时客户端也会)就可以使⽤ access token 作为⽤户授权的令牌,向授权⽅⽹站发送请求来获取⽤户信息或操作⽤户账户。但这已经在 OAuth 流程之外。
-
-
为什么 OAuth 要引⼊ Authorization code,并需要申请授权的第三⽅将 Authorization code 发送回⾃⼰的服务器,再从服务器来获取 access token,⽽不是直接返回 access token ?这样复杂的流程意义何在?
为了安全。OAuth不强制授权流程必须使⽤ HTTPS,因此需要保证当通信路径中存在窃听者时,依然具有⾜够⾼的安全性。
-
第三⽅ App 通过微信登录的流程(也是⼀个 OAuth2 流程):
-
第三⽅ App 向腾讯申请第三⽅授权合作,拿到 client id 和 client secret
-
⽤户在使⽤第三⽅ App 时,点击「通过微信登录」,第三⽅ App 将使⽤微信 SDK 跳转到微信,并传⼊⾃⼰的 client id 作为⾃⼰的身份标识
-
微信通过和服务器交互,拿到第三⽅ App 的信息,并限制在界⾯中,然后询问⽤户是否同意授权该 App 使⽤微信来登录
-
⽤户点击「使⽤微信登录」后,微信和服务器交互将授权信息提交,然后跳转回第三⽅ App,并传⼊ Authorization code 作为⽤户认可的凭证
-
第三⽅ App 调⽤⾃⼰服务器的「微信登录」Api,并传⼊ Authorizationcode,然后等待服务器的响应
-
服务器在收到登录请求后,拿收到的 Authorization code 去向微信的第三⽅授权接⼝发送请求,将 Authorization code 和⾃⼰的 client secret ⼀起作为参数发送,微信在验证通过后,返回 access token
-
服务器在收到 access token 后,⽴即拿着 access token 去向微信的⽤户信息接⼝发送请求,微信验证通过后,返回⽤户信息
-
服务器在收到⽤户信息后,在⾃⼰的数据库中为⽤户创建⼀个账户,并使⽤从微信服务器拿来的⽤户信息填⼊⾃⼰的数据库,以及将⽤户的 ID 和⽤户\的微信 ID 做关联
-
⽤户创建完成后,服务器向客户端的请求发送响应,传送回刚创建好的⽤户信息
-
客户端收到服务器响应,⽤户登录成功
-
-
在⾃家 App 中使⽤ Bearer token
有的 App 会在 Api 的设计中,将登录和授权设计成类似 OAuth2 的过程,但简化掉 Authorization code 概念。即:登录接⼝请求成功时,会返回 access token,然后客户端在之后的请求中,就可以使⽤这个 access token 来当做 bearer token 进⾏⽤户操作了。
-
Refresh token
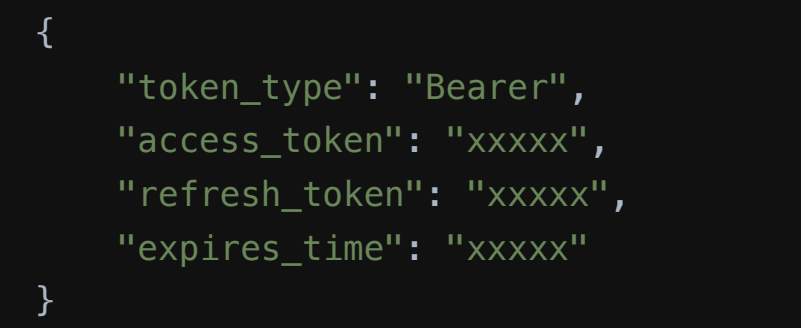
- ⽤法:access token 有失效时间,在它失效后,调⽤ refresh token 接⼝,传⼊refresh_token 来获取新的 access token。
- ⽬的:安全。当 access token 失窃,由于它有失效时间,因此坏⼈只有较短的时间来「做坏事」;同时,由于(在标准的 OAuth2 流程中)refresh token 永远只存在与第三⽅服务的服务器中,因此 refresh token ⼏乎没有失窃的⻛险。